






Apache Drill
Schema-free 类型的SQL引擎,
专为Hadoop,NoSQL和
云存储设计
现在下载
敏捷性获得更快的洞察力又省去繁琐的前置处理(Schema创建和维护、数据加载、转换等ETL操作) |
灵活性直接分析NoSQL中的复杂结构和嵌套数据(无需转换和要求数据格式) |
易用性充分利用你已具备的SQL技术栈和BI工具,包括Tableau, Qlikview, MicroStrategy, Spotfire, Excel等等。 |

无处不在:几乎可以查询任何类型的NoSQL数据库
Drill支持多种类型的NoSQL数据库和文件系统, 包含 Hbase、MongoDB、ElasticSearch、Cassandra、Druid、Kudu、Kafka、OpenTSDB、HDFS、Amazon S3、Azure Blob Storage、Google Cloud Storage、Swift、NAS和本地文件。可以在单次查询中组合多个数据源(联邦查询)。
Drill的存储感知优化器会利用数据存储的内部处理能力来重构查询计划。Drill还支持数据本地性(Data Locality),所以将Drill和数据节点部署在一起可以充分优化性能。
告别繁冗:充分享受数据应用的敏捷性
传统的查询引擎需要大量的IT交互才允许查询数据。Drill直接省去了这些冗余,可以快速原地查询这些原始数据。没有Schema创建和维护,也没有数据加载、转换和ETL操作。只需要在查询语句中指定数据的位置,如 Hadoop、S3或MongoDB。
Drill利用先进的查询编译和重编译,来优化查询性能,而不必对数据模式有预先了解。
SELECT * FROM dfs.root.`/web/logs`; SELECT country, count(*) FROM mongodb.web.users GROUP BY country; SELECT timestamp FROM s3.root.`clicks.json` WHERE user_id = 'jdoe';
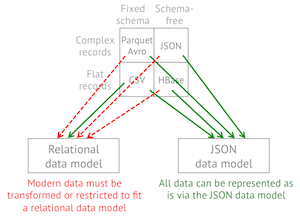
化繁为简:将任何数据当表格形式一样使用
Drill设计了专有的JSON数据模型,能够支持复杂/嵌套数据的查询,对现代应用程序以及NoSQL中快速衍化的数据结构进行分析。不仅于此,还提供了SQL的扩展性,轻松查询更复杂的数据结构。
Drill是一款支持复杂数据的列式查询引擎。而且支持在内存中用列式表达复杂数据,所以查询JSON数据模型的速度可以媲美列式格式。
简单易用:继续使用你喜欢的BI工具
Drill支持标准的 ANSI SQL。商务用户,分析师,数据科学家可以通过Drill的JDBC或者ODBC驱动在标准的BI和分析工具上运行,例如:Tableau, Qlik, MicroStrategy, Spotfire, SAS 和 Excel,开发者也可以在他们的应用中使用 RESTful API(支持流式响应)来定制数据可视化。
Drill的虚拟数据集可以将复杂的NoSQL数据结构对应到兼容BI的结构,帮助用户挖掘和可视化数据。

$ curl -L "<url>" | tar xzf - $ cd apache-drill-<version> $ bin/drill-embedded
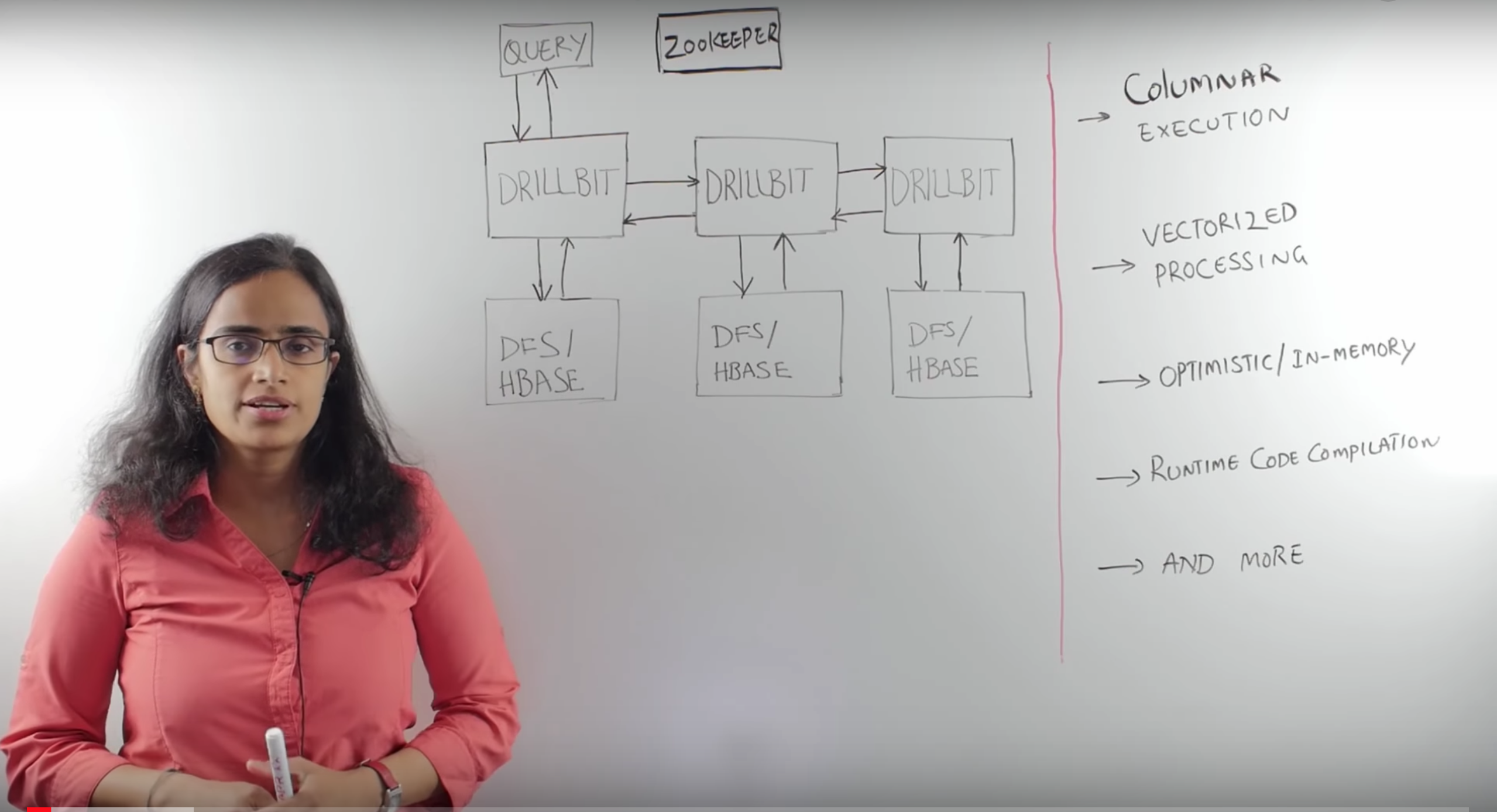
水平扩展:从一台主机到一千台服务器
Drill开箱即用的特点可以支持在Mac、Windows和Linux上快速完成安装(分钟级)。针对大规模的数据集,也可以部署到商用服务器上,充分利用高性能引擎。
Drill的对称性架构(所有节点职责相同)和易于安装的特点,方便部署及运行在大规模集群上。
$ curl <url> -o drill.tgz $ tar xzf drill.tgz $ cd apache-drill-<version> $ bin/drill-embedded
快速响应:不再需要等待你的咖啡
Drill并不是世界上第一款查询引擎,却是第一个兼顾数据复杂性和查询速度的MPP引擎。Drill设计了与众不同的架构,不仅能够支持JSON数据模型,还做到了非凡的响应速度。
- 列式执行引擎 (第一款支持复杂数据的列式执行引擎)
- 支持运行时期的 Data-driven 编译和重编译。
- 专有的内存管理技术以减少内存占用和避免频繁垃圾回收
- 通过将Drill和数据节点部署在一起来支持数据本地性(Data Locality)
- 利用查询优化器的CBO和RBO技术将查询尽可能下推到数据库
